 logstash提取日志字段到kibana仪表盘展示
logstash提取日志字段到kibana仪表盘展示
# 一、日志分析
# 需要处理的日志
{"@timestamp":"2023-04-16T00:03:36.946+08:00","caller":"logic/sendticklogic.go:37","content":"recv tick err: rpc error: code = Canceled desc = context canceled","level":"error","span":"1e4c82625afe0758","trace":"2b96e538e67df5cc7c8218ee35c11d71"}
1
创建一个Grok模式来匹配日志中的各个字段
日志
2023-04-16T00:03:36.946+08:00|logic/sendticklogic.go:37|recv tick err: rpc error: code = Canceled desc = context canceled|error|1e4c82625afe0758|2b96e538e67df5cc7c8218ee35c11d71
1
grok模式
%{TIMESTAMP_ISO8601:@timestamp}\|%{DATA:caller}\|%{GREEDYDATA:content}\|%{DATA:level}\|%{DATA:span}\|%{DATA:trace}
1
将这个日志示例和Grok模式粘贴到在线Grok调试器中,您应该能够看到以下匹配结果:
- @timestamp: "2023-04-16T00:03:36.946+08:00"
- caller: "logic/sendticklogic.go:37"
- content: "recv tick err: rpc error: code = Canceled desc = context canceled"
- level: "error"
- span: "1e4c82625afe0758"
- trace: "2b96e538e67df5cc7c8218ee35c11d71"
这个结果与之前所述的字段相匹配。使用Grok调试器,您可以测试和优化Grok模式,以便准确地匹配您的日志数据
# 二、logstash提取日志字段
# 在filter中使用grok过滤器
具体内容如下
input {
kafka {
type => "pro-ait0-go-error"
bootstrap_servers => ["xxx:9093, xxx:9094, xxx:9095"]
client_id => "pro-ait0-go-error"
group_id => "pro-ait0-go-error"
auto_offset_reset =>"latest"
topics => ["pro-ait0-go-error"]
consumer_threads => 6
codec => "json"
}
}
filter {
grok {
match => { "message" => '"content":"%{GREEDYDATA:content_value}"' }
}
}
output {
if [type] == "pro-ait0-go-error" {
elasticsearch {
hosts => ["http://xxx:9200"]
user => "elastic"
password => "t1Nc9SSHBiFOQK01R44l"
index => "pro-ait0-go-error-%{+YYYY.MM.dd}"
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 三、kibana仪表盘设置
# 创建索引
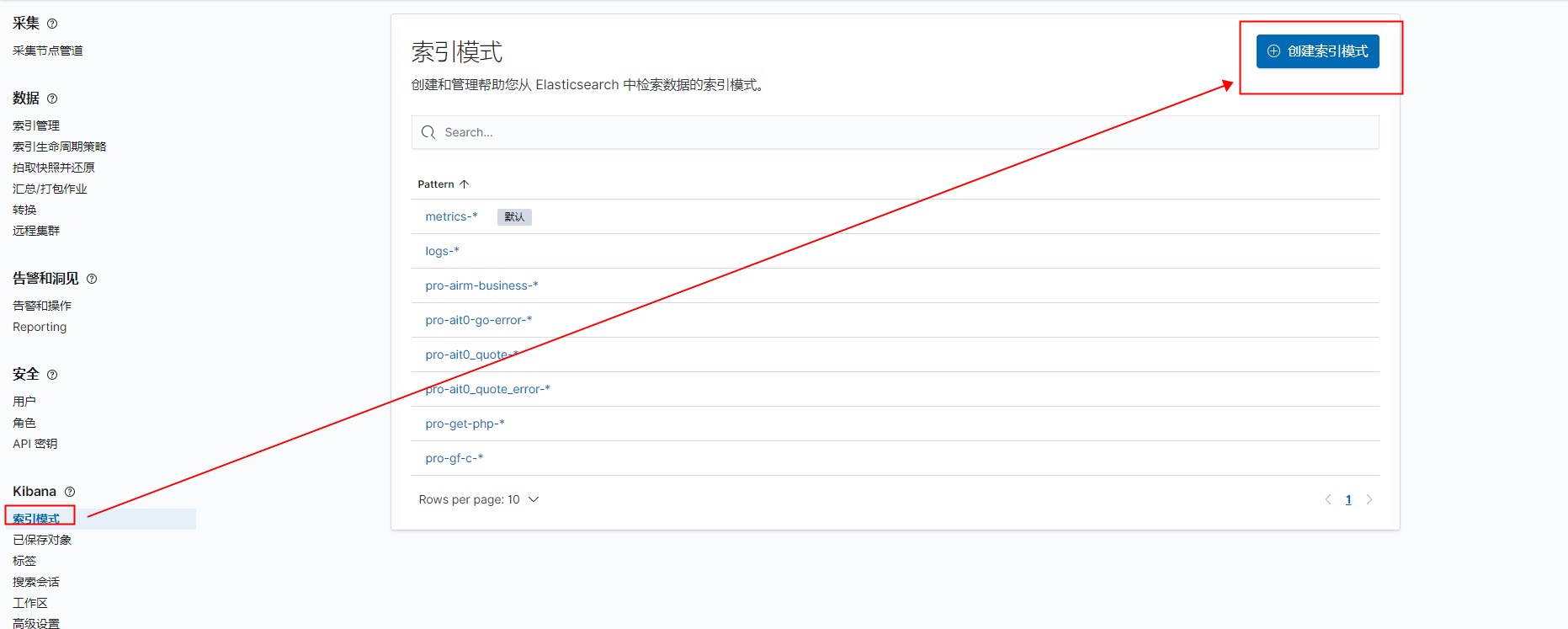
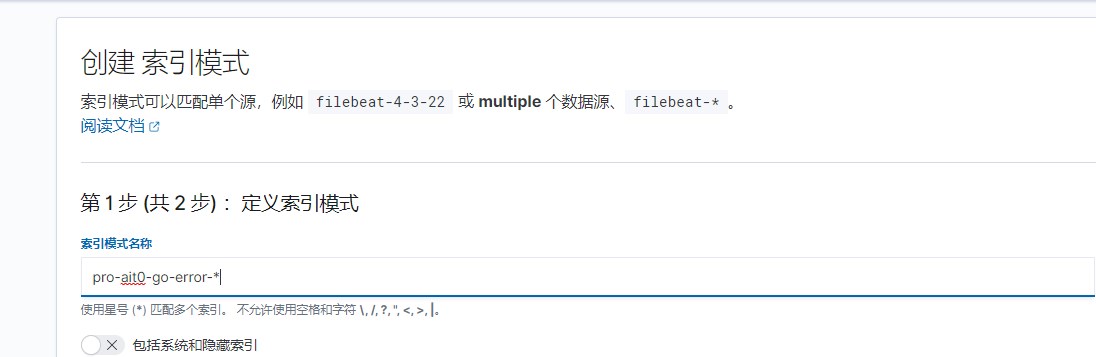
# 打开dashboard仪表盘,创建仪表盘,创建面板,选择可视化lens

# 选择对应索引,将字段拖到开始处


上次更新: 2023/04/21, 08:57:47
 |
|