 部署ceph集群 Nautilus版
部署ceph集群 Nautilus版
学习ceph第一天,记录下ceph集群部署过程
参考文档:
# ceph简介
# ceph架构
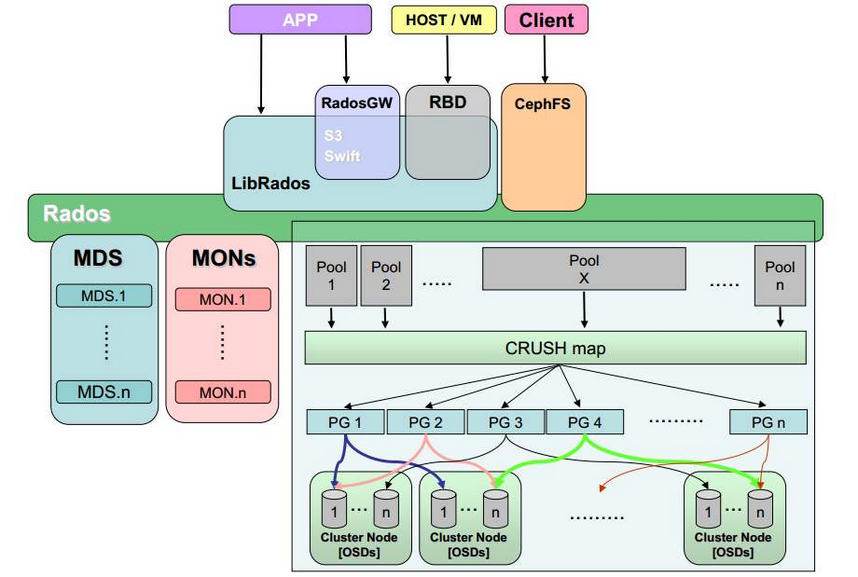
# Ceph 支持三种接口
- Object:有原生的API,而且也兼容 Swift 和 S3 的 API
- Block:支持精简配置、快照、克隆
- File:Posix 接口,支持快照
# ceph主要特点
- 统一存储
- 无任何单点故障
- 数据多份冗余
- 存储容量可扩展
- 自动容错及故障自愈
# ceph核心组件及其作用
在Ceph存储集群中,包含了三大角色组件,他们在Ceph存储集群中表现为3个守护进程,分别是Ceph OSD、Monitor、Managers。当然还有其他的功能组件,但是最主要的是这三个。
- Ceph OSD: Ceph的OSD(Object Storage Device)守护进程。主要功能包括:存储数据、副本数据处理、数据恢复、数据回补、平衡数据分布,并将数据相关的一些监控信息提供给Ceph Moniter,以便Ceph Moniter来检查其他OSD的心跳状态。一个Ceph OSD存储集群,要求至少两个Ceph OSD,才能有效的保存两份数据。注意,这里的两个Ceph OSD是指运行在两台物理服务器上,并不是在一台物理服务器上运行两个Ceph OSD的守护进程。通常,冗余和高可用性至少需要3个Ceph OSD。
- Monitor: Ceph的Monitor守护进程,主要功能是维护集群状态的表组,这个表组中包含了多张表,其中有Moniter map、OSD map、PG(Placement Group) map、CRUSH map。 这些映射是Ceph守护进程之间相互协调的关键簇状态。 监视器还负责管理守护进程和客户端之间的身份验证。 通常需要至少三个监视器来实现冗余和高可用性。
- Managers: Ceph的Managers(Ceph Manager),守护进程(ceph-mgr)负责跟踪运行时间指标和Ceph群集的当前状态,包括存储利用率,当前性能指标和系统负载。 Ceph Manager守护程序还托管基于python的插件来管理和公开Ceph集群信息,包括基于Web的仪表板和REST API。 通常,至少有两名Manager需要高可用性。
- MDS: Ceph的MDS(Metadata Server)守护进程,主要保存的是Ceph文件系统的元数据。注意,对于Ceph的块设备和Ceph对象存储都不需要Ceph MDS守护进程。Ceph MDS为基于POSIX文件系统的用户提供了一些基础命令的执行,比如ls、find等,这样可以很大程度降低Ceph存储集群的压力。
# ceph应用场景
Ceph的应用场景主要由它的架构确定,Ceph提供对象存储、块存储和文件存储,主要由以下4种应用场景:
- LIBRADOS应用: 通俗的说,Librados提供了应用程序对RADOS的直接访问,目前Librados已经提供了对C、C++、Java、Python、Ruby和PHP的支持。它支持单个单项的原子操作,如同时更新数据和属性、CAS操作,同时有对象粒度的快照操作。它的实现是基于RADOS的插件API,也就是在RADOS上运行的封装库。
- RADOSGW应用: 这类应用基于Librados之上,增加了HTTP协议,提供RESTful接口并且兼容S3、Swfit接口。RADOSGW将Ceph集群作为分布式对象存储,对外提供服务。
- RBD应用: 这类应用也是基于Librados之上的,细分为下面两种应用场景。
- 第一种应用场景为虚拟机提供块设备。通过Librbd可以创建一个块设备(Container),然后通过QEMU/KVM附加到VM上。通过Container和VM的解耦,使得块设备可以被绑定到不同的VM上。
- 第二种应用场景为主机提供块设备。这种场景是传统意义上的理解的块存储。
- 以上两种方式都是将一个虚拟的块设备分片存储在RADOS中,都会利用数据条带化提高数据并行传输,都支持块设备的快照、COW(Copy-On-Write)克隆。最重要的是RBD还支持Live migration。
- CephFS(Ceph文件系统)应用: 这类应用是基于RADOS实现的PB级分布式文件系统,其中引入MDS(Meta Date Server),它主要为兼容POSIX文件系统提供元数据,比如文件目录和文件元数据。同时MDS会将元数据存储在RADOS中,这样元数据本身也达到了并行化,可以大大加快文件操作的速度。MDS本身不为Client提供数据文件,只为Client提供对元数据的操作。当Client打开一个文件时,会查询并更新MDS相应的元数据(如文件包括的对象信息),然后再根据提供的对象信息直接从RADOS中得到文件数据。
# 环境准备
| OS | hostname | ip | roles |
|---|---|---|---|
| Centos 7.5 | pod4-core-20-10 | 192.168.20.10 / 192.168.30.10 | ceph-deploy、monitor、Managers、rgw、mds |
| Centos 7.5 | pod4-core-20-5 | 192.168.20.5 / 192.168.30.5 | monitor、Managers、rgw、mds |
| Centos 7.5 | pod4-core-20-6 | 192.168.20.6 / 192.168.30.6 | monitor、Managers、rgw、mds |
注:每个节点有两块硬盘、两块网卡以便测试,使用ceph-deploy工具部署ceph存储。
# 系统初始化
系统初始化这一小节的所有操作,没有特别注明的,均需在所有节点上执行。
# 关闭防火墙及selinux
# 关防火墙
$ systemctl stop firewalld && systemctl disable firewalld
# 关selinux
setenforce 0
sed -i 's#^SELINUX=.*#SELINUX=disabled#g' /etc/selinux/config
sed -i 's#^SELINUX=.*#SELINUX=disabled#g' /etc/sysconfig/selinux
2
3
4
5
6
7
# 修改主机名
# 将 HOSTNAME 替换为你实际主机名
$ hostnamectl set-hostname HOSTNAME
# 所有节点执行刷新生效
bash
source /etc/profile
2
3
4
5
6
7
# 配置hosts解析记录
$ cat >> /etc/hosts << EOF192.168.20.10 pod4-core-20-10192.168.20.5 pod4-core-20-5192.168.20.6 pod4-core-20-6EOF
# 调整内核参数
$ cat > /etc/sysctl.conf << EOFkernel.sysrq = 0kernel.core_uses_pid = 1fs.file-max=655360kernel.msgmnb = 65536kernel.msgmax = 65536kernel.shmmax = 68719476736kernel.shmall = 4294967296kernel.pid_max = 655360net.ipv4.tcp_tw_reuse = 1net.ipv4.tcp_tw_recycle = 0net.ipv4.tcp_max_tw_buckets = 262144net.ipv4.tcp_fin_timeout = 30net.ipv4.tcp_timestamps = 0net.ipv4.tcp_sack = 1net.ipv4.tcp_window_scaling = 1net.ipv4.tcp_ecn = 0net.ipv4.tcp_keepalive_time = 600net.ipv4.tcp_keepalive_intvl = 30net.ipv4.tcp_keepalive_probes = 3net.ipv4.tcp_max_orphans = 655360net.ipv4.tcp_max_syn_backlog = 262144net.ipv4.tcp_mem = 65536 131072 262144net.ipv4.udp_mem = 65536 131072 262144net.ipv4.tcp_rmem = 4096 87380 16777216net.ipv4.tcp_wmem = 4096 16384 16777216net.ipv4.ip_local_port_range = 1024 65535net.ipv4.route.gc_timeout = 100# 禁止icmp重定向报文net.ipv4.conf.all.accept_redirects = 0# 禁止icmp源路由net.ipv4.conf.all.accept_source_route = 0net.core.somaxconn = 65535net.core.rmem_default = 8388608net.core.wmem_default = 8388608net.core.rmem_max = 16777216net.core.wmem_max = 16777216net.core.netdev_max_backlog = 262144vm.swappiness = 3vm.overcommit_memory = 1vm.max_map_count = 262144EOF
# 刷新生效
sysctl -p
2
3
4
# 调整最大可打开文件数
$ mv /etc/security/limits.conf{,.bak}
cat > /etc/security/limits.conf << EOF* - nofile 650000* - memlock unlimited* - stack 655360* - nproc unlimitedEOF
2
执行此操作后,需要重新打开终端,才可生效。
# 配置ntp
# 配置ntp服务端
在pod4-core-20-10上执行这些步骤。
# 安装软件包
$ yum -y install chrony
# 编辑配置文件
$ mv /etc/chrony.conf{,.bak}
cat > /etc/chrony.conf << EOFbindcmdaddress 0.0.0.0server ntp.aliyun.com iburstallow 192.168.20.0/24driftfile /var/lib/chrony/driftmakestep 1.0 3rtcsynclogdir /var/log/chronyEOF
# 启动chronyd
systemctl enable chronyd && systemctl restart chronyd
2
3
4
5
6
7
8
9
# 其他节点同步控制节点时间
在其他所有节点执行此操作。
# 安装软件包
$ yum -y install chrony
# 编辑配置文件
$ mv /etc/chrony.conf{,.bak}
cat > /etc/chrony.conf << EOFserver pod4-core-20-10 iburstdriftfile /var/lib/chrony/driftmakestep 1.0 3rtcsynclogdir /var/log/chronyEOF
$ systemctl enable chronyd && systemctl restart chronyd
# 最好先手动测试下,可以同步时间
$ yum -y install ntp
$ ntpdate -u 192.168.20.10
2
3
4
5
6
7
8
9
10
11
# 配置yum源
# 更换为阿里云源
$ mkdir /etc/yum.repos.d/bak
mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/bak/
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum clean all && yum makecache fast
# 配置ceph-nautilus源
cat > /etc/yum.repos.d/ceph.repo << "EOF"[ceph-norch]name=ceph-norchbaseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/enabled=1gpgcheck=0[ceph-x86_64]name=ceph-x86_64 baseurl=https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/x86_64/enabled=1gpgcheck=0EOF
yum clean all
yum makecache fast
2
3
4
5
6
7
8
9
10
11
12
接下来的操作,如果没有特殊说明,均在 pod4-core-20-10节点执行。
# 安装基础工具
$ yum -y install python-setuptools ceph-deploy
$ ceph-deploy --version # 确保ceph-deploy版本为2.0.1
2.0.1
2
3
4
# 配置免密登录到其他节点
$ ssh-keygen -t rsa -q
for i in 5 6 10;do ssh-copy-id pod4-core-20-$i;done # 根据提示输入相应密码
2
# 部署ceph集群
接下来的操作,如果没有特殊说明,均在 pod4-core-20-10节点执行。
# 部署admin
创建一个Ceph Monitor和三个Ceph OSD守护进程的Ceph存储集群。集群达到状态后,通过添加第四个Ceph OSD守护程序,一个元数据服务器和两个以上的Ceph Monitors对其进行扩展。
$ mkdir my-cluster && cd my-cluster
$ ceph-deploy new --public-network 192.168.20.0/24 \
--cluster-network 192.168.30.0/24 pod4-core-20-10
# --public-network:对外网络,用于客户端访问
# --cluster-network:集群内部信息同步网络
# pod4-core-20-10:将此节点设置为Monitor节点
2
3
4
5
6
7
上述命令执行后,输出如下:
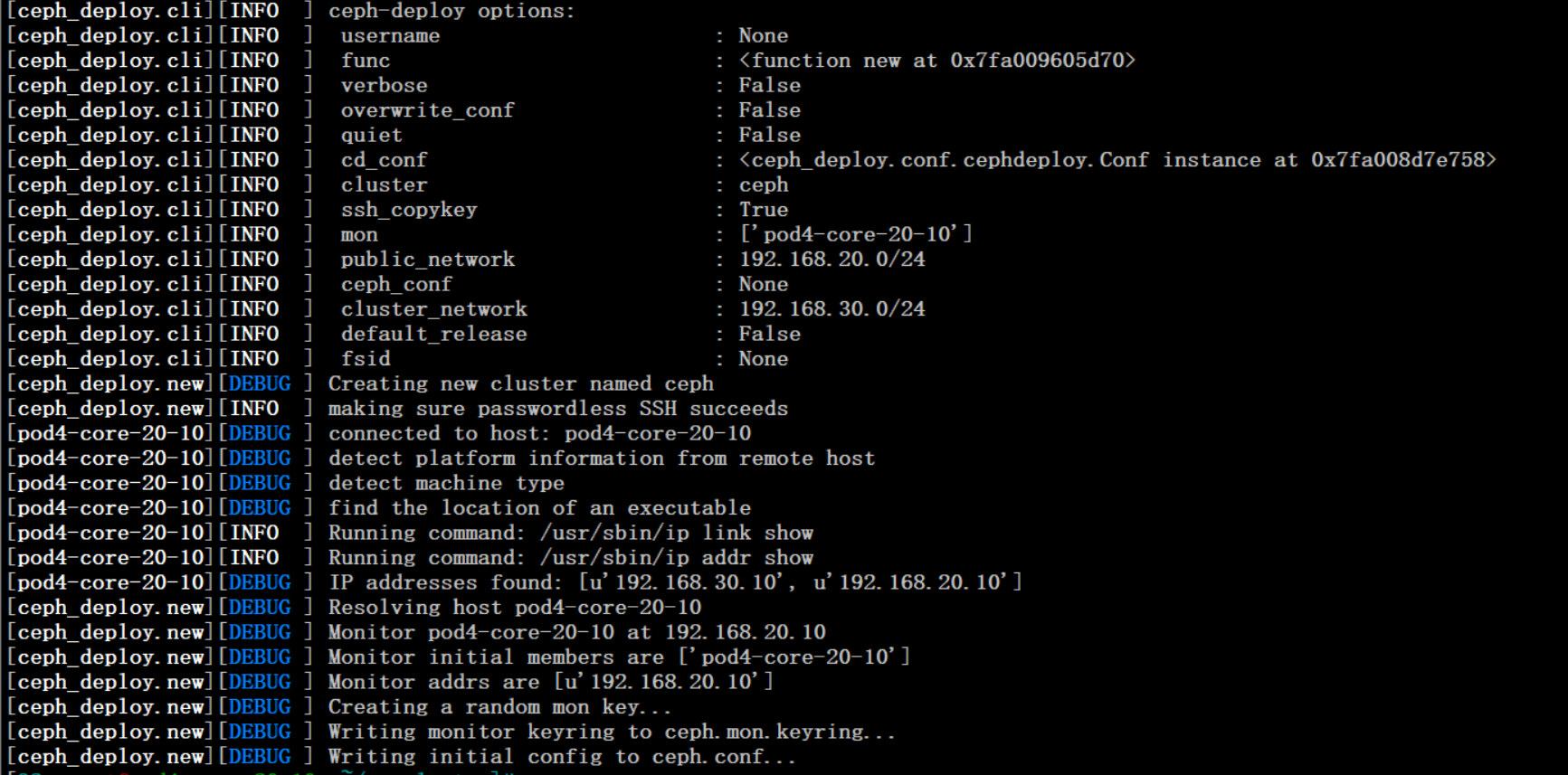
$ ls # 命令执行成功后,会生成配置文件、日志文件、秘钥文件
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring
$ cat ceph.conf # 生成的配置文件内容如下
# 如果有错误之处,可以根据自己实际情况修改
[global]
fsid = 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
public_network = 192.168.20.0/24
cluster_network = 192.168.30.0/24
mon_initial_members = pod4-core-20-10
mon_host = 192.168.20.10
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
2
3
4
5
6
7
8
9
10
11
12
13
# 安装ceph软件包
仅安装ceph软件包此操作在所有节点执行
# 不要使用官方提供的 ceph-deploy install 命令进行安装,它会自己再配置yum源,安装较慢
$ yum -y install ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds
2
# 初始化monitor
接下来的操作,如果没有特殊说明,均在 pod4-core-20-10节点执行。
$ ceph-deploy mon create-initial
# 拷贝admin的秘钥文件
# admin后面指定ceph集群中的所有节点
$ ceph-deploy admin pod4-core-20-10 pod4-core-20-5 pod4-core-20-6
2
# 确认集群状态
$ ceph -s
cluster:
id: 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
health: HEALTH_OK
services:
mon: 1 daemons, quorum pod4-core-20-10 (age 2m) # 包含一个monitor
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 部署manager
# 将manager守护程序部署在 pod4-core-20-10
$ ceph-deploy mgr create pod4-core-20-10
$ ceph -s # 查看集群状态
cluster:
id: 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum pod4-core-20-10 (age 8m)
mgr: pod4-core-20-10(active, since 41s) # 新增一个manager节点
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 创建三个OSD
每个机器至少需要一块全新硬盘,确保没有被格式化过。
$ ceph-deploy osd create --data /dev/sdb pod4-core-20-10
ceph-deploy osd create --data /dev/sdb pod4-core-20-5
ceph-deploy osd create --data /dev/sdb pod4-core-20-6
$ ceph -s # 查看集群状态
cluster:
id: 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
health: HEALTH_OK
services:
mon: 1 daemons, quorum pod4-core-20-10 (age 14m)
mgr: pod4-core-20-10(active, since 6m)
osd: 3 osds: 3 up (since 30s), 3 in (since 30s) # 包含了三个osd
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
$ ceph osd tree # 查看osd详细信息
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05846 root default
-3 0.01949 host pod4-core-20-10
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host pod4-core-20-5
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.01949 host pod4-core-20-6
2 hdd 0.01949 osd.2 up 1.00000 1.00000
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# ceph集群扩容
# 扩容monitor节点
一个Ceph存储集群至少需要一个Ceph Monitor和Ceph Manager才能运行。为了获得高可用性,Ceph存储群集通常运行多个Ceph Monitor,这样可以避免单点故障。
Ceph使用Paxos算法,节点数量最好是奇数(即,大于N / 2,其中N是Monitor的数量)才能形成仲裁。尽管这不是必需的。
# 扩容第一个monitor节点
# 添加 pod4-core-20-5为monitor节点
$ ceph-deploy mon add pod4-core-20-5
$ ceph quorum_status --format json-pretty # 检查仲裁状态
{
"election_epoch": 8,
"quorum": [
0,
1
],
"quorum_names": [ # 加入仲裁的节点
"pod4-core-20-10",
"pod4-core-20-5"
],
"quorum_leader_name": "pod4-core-20-10", # 当前leader
"quorum_age": 210,
"monmap": {
"epoch": 2,
"fsid": "634fc0a4-d2bd-4f14-af6b-421ecbb89ba6",
"modified": "2021-02-21 15:46:00.889286",
"created": "2021-02-21 15:21:30.739161",
"min_mon_release": 14,
"min_mon_release_name": "nautilus",
"features": {
"persistent": [
"kraken",
"luminous",
"mimic",
"osdmap-prune",
"nautilus"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "pod4-core-20-10",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.20.10:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.20.10:6789",
"nonce": 0
}
]
},
"addr": "192.168.20.10:6789/0",
"public_addr": "192.168.20.10:6789/0"
},
{
"rank": 1,
"name": "pod4-core-20-5",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.20.5:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.20.5:6789",
"nonce": 0
}
]
},
"addr": "192.168.20.5:6789/0",
"public_addr": "192.168.20.5:6789/0"
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# 扩容第二个monitor节点
# 添加 pod4-core-20-6为monitor节点
$ ceph-deploy mon add pod4-core-20-6
# 确认三个节点加入仲裁
$ ceph quorum_status --format json-pretty
{
"election_epoch": 12,
"quorum": [
0,
1,
2
],
"quorum_names": [
"pod4-core-20-10",
"pod4-core-20-5",
"pod4-core-20-6"
],
"quorum_leader_name": "pod4-core-20-10",
"quorum_age": 30,
....... # 省略部分输出
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 检查ceph集群状态
$ ceph -s
cluster:
id: 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
health: HEALTH_OK
services: #确保有三个monitor
mon: 3 daemons, quorum pod4-core-20-10,pod4-core-20-5,pod4-core-20-6 (age 64s)
mgr: pod4-core-20-10(active, since 25m)
osd: 3 osds: 3 up (since 19m), 3 in (since 19m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
$ ceph mon stat # 也可以单独查看monitor状态
e3: 3 mons at {pod4-core-20-10=[v2:192.168.20.10:3300/0,v1:192.168.20.10:6789/0],
pod4-core-20-5=[v2:192.168.20.5:3300/0,v1:192.168.20.5:6789/0],
pod4-core-20-6=[v2:192.168.20.6:3300/0,v1:192.168.20.6:6789/0]},
election epoch 12, leader 0 pod4-core-20-10, quorum 0,1,2
pod4-core-20-10,pod4-core-20-5,pod4-core-20-6
$ ceph mon dump # dump查看monitor状态
dumped monmap epoch 3
epoch 3
fsid 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
last_changed 2021-02-21 15:53:36.055686
created 2021-02-21 15:21:30.739161
min_mon_release 14 (nautilus)
0: [v2:192.168.20.10:3300/0,v1:192.168.20.10:6789/0] mon.pod4-core-20-10
1: [v2:192.168.20.5:3300/0,v1:192.168.20.5:6789/0] mon.pod4-core-20-5
2: [v2:192.168.20.6:3300/0,v1:192.168.20.6:6789/0] mon.pod4-core-20-6
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 扩容manager节点
Ceph Manager守护进程以 active/standby 模式运行。当前active节点宕机后,处于standby状态的会自动提升为active节点。
# 将pod4-core-20-5、pod4-core-20-6添加到manager集群
$ ceph-deploy mgr create pod4-core-20-5 pod4-core-20-6
# 添加成功后,确认集群状态
$ ceph -s
cluster:
id: 634fc0a4-d2bd-4f14-af6b-421ecbb89ba6
health: HEALTH_OK
services:
mon: 3 daemons, quorum pod4-core-20-10,pod4-core-20-5,pod4-core-20-6 (age 8m)
mgr: pod4-core-20-10(active, since 32m), standbys: pod4-core-20-5, pod4-core-20-6
osd: 3 osds: 3 up (since 26m), 3 in (since 26m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
至此,ceph集群部署完成。
原文链接:
https://lvjianzhao.gitee.io/lvjianzhao/posts/6010b413/?highlight=ceph


 |
|